coreference resolution
상호참조해결 (coreference resolution)
Coreference : 텍스트 안에서 Real world 에 존재하는 entity를 모두 찾아내는것
- 상호참조해결
자연어로 이루어진 문서에서 나타나는 명사구들에 대해 서로 같은 개체를 뜻하는 언급(mention)들을 찾는 작업.
-> 축약어나 대명사, 지시 관형사등과 같이 다른 형태로 등장하는 경우가 있 기 때문에 명사구 간의 상호참조 관계를 밝힌다.
문서요약, 질의응답, 정보 추출, 문서분류등 과 같은 자연언어처리 문제에 사용할 수 있다.
- 용어 정리
참조 : 단어가 변형되거나 혹은 대명사 형태 와 같이 축약된 명사구들로 나타나는 것
상호 참조 해결 : 명사구 간의 참조 관계를 명확히 밝혀 주는 과정
대용어해결(anaphora resolution) : 문서 내에서 이전에 언급된 표현이나 의미를 받아와 다시 사용하는 것
문맥상에서 전이 적인 특징만 가진다(즉, A -> B)
멘션(Mention) : 상호참조해결의 대상이 되는 모든 명사구(즉, 명사, 명사구 등)를 의미
중심어(head) : 멘션에서 해당 구의 실질적인 의미를 나타내는 단어
- 상호참조 해결이 필요한 이유
개체명, 구문분석기 등이 지식베이스에서 명확해져 지식추출 성능 향상에 기여
ex) 버락 오바마는 미국의 대통령이다. 그의 출생지 는 미국 하와이주 호놀롤루이다
<버락_오바마, isA, 미국의_대통령>, <버락_오바마, birth_place, 미국_하와이주_호놀롤 루>
-> 이러한 것을 “지식트리플 추출” 이라 한다.
관련 연구
- 규칙 기반
선행사들에 대하여 문법적인 특성과 등장한 위치, 개체명, 성별, 인칭 ,단복수 등의 의미에 따라 일관성 있는 규칙을 정의
- 통계 기반
기계학습등을 이용한 방법으로, 일반적으로 규칙 기반에 비해 보다 좋은 성능을 보이지만, 자질 디자인이 잘 되어야 한다는 제약이 있다.
- Corefernece - Hobb’s naive algorithm
전통적인 방법으로 구문 구조에 대한 이해를 바탕으로 규칙을 만듦
- SpanBERT
2020년 1월 18일, https://arxiv.org/pdf/1907.10529v3.pdf
text span을 잘 표현하고 예측하도록 design된 pre-train 방법인 SpanBERT를 제안
2019년 7월 워싱턴대, 프린스턴대, AllenAI 연구소, 페이스북에서 수행한 연구
- 제안
(1) random token이 아닌 contiguous한 random span을 마스킹
(2) 개별 token representation에 의존하지 않고 mask 범위의 전체 내용을 예측 하도록 span boundary representation을 학습
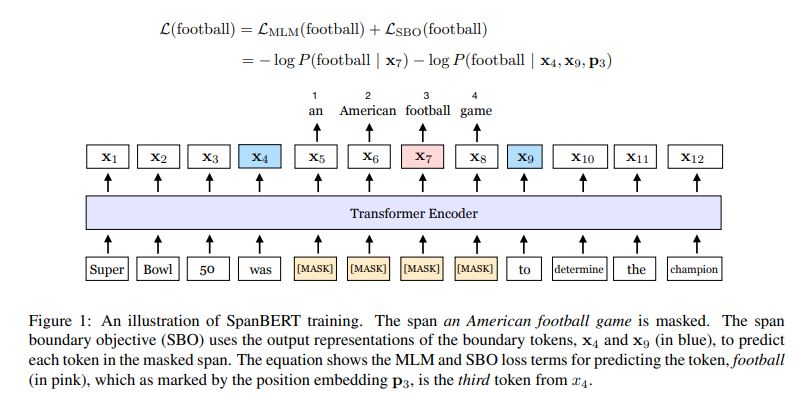
- 학습 방법
1. Span Masking
연속된 span 단위로 각 토큰에 대해서 [MASK] 토큰을 변환하였다.
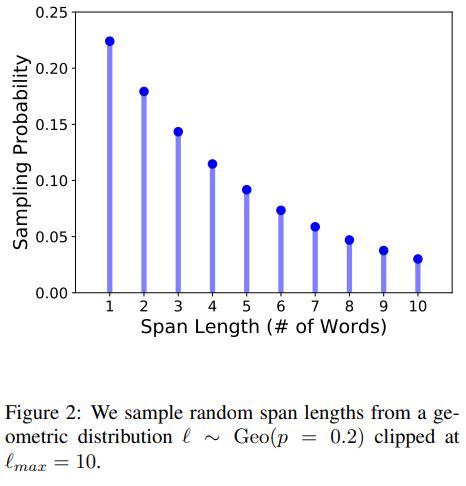
span의 길이를 geometric distribution에 의해 선택되고, 랜덤하게 span의 시작위치를 선택
위 사진은 Span의 길이 분포
2. Span Boundary Objective(SBO)
[MASK]로 변환된 단어의 원 단어 토큰을 추론할 때, 해당 단어의 출력 벡터로부터 추론하는 loss 외에 span의 경계에 위치한 단어의 출력 벡터로부터 해당 단어를 추론하는 loss를 추가하여 학습
SpanBERT상위 그림에서, 7번째 단어가 football일 때, x7 출력 토큰을 이용하여 football을 예측하는 loss와 span의 경계에 해당하는 x4 및 x9와 해당 단어의 위치인 p7을 이용하여 football을 예측하는 loss를 결합하여 사용한다.
3. NLP태스크 제외
두 segment를 결합하여 NLP태스크를 수행한것을 단을 segment로 입력을 구성한 경우 성능이 개선됨
- ProBERT
2019년 8월 2일, https://www.aclweb.org/anthology/W19-3820.pdf
- GPT-3 175B (Few-Shot)
2020년 2월 22일, https://arxiv.org/pdf/2005.14165v4.pdf
데이터
- 상호 참조 해결 말뭉치 구축 - 국립국어원
2020년 1월 15일 보고서 작성
-> 2021년 데이터 공개 예정 (국어국립원 전화로 확인)
- ETRI
엑소브레인 언어분석 말뭉치
http://aiopen.etri.re.kr/service_dataset.php
퀴즈 도메인(장학퀴즈와 위키백과QA)의 질문문서, 말뭉치
| 필드 | 설명 |
|---|---|
| id | 엔티티의 인덱스 |
| type | 개체명 레이블 정보 |
| number | 엔티티의 단 , 복수 정보 |
| gender | 엔티티의 성별 정보 |
| person | 엔티티의 인칭 정보 |
| animacy | 엔티티의 생물/무생물 구분 정보 |
| mention | 엔티티에 포함된 멘션들의 정보 |
- 국전자통신연구원_한국어 언어분석 통합 말뭉치
최종 수정 : 2020-02-04 url : https://www.data.go.kr/data/15042734/fileData.do 전화로 물어본 결과 : 2021년 데이터 오픈 예정
- kaist에서 공개한 일부 데이터
https://github.com/shingiyeon/KoreanCoreferenceResolution
- 영어
https://github.com/ontonotes/conll-formatted-ontonotes-5.0
https://catalog.ldc.upenn.edu/LDC2001T02
http://conll.cemantix.org/2011/data.html
데이터 입출력 예시
SPAN-BERT를 기반으로 작성
https://arxiv.org/pdf/1907.10529.pdf
-
입력 문장
["I voted for Obama because he was most aligned with my values", "she said."]
-
입력 데이터 예시
컬럼 명 값 비고 cluster [] 비워둬야 하며 평가 목적으로 사용 dock_key nw 장르를 나타내며 다음 중 하나 [“bc”, “bn”, “mz”, “nw”, “pt”, “tc”, “wb”] sentence_map [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0] sentence [[“[CLS]”, “I”, “voted”, “for”, “Obama”, “because”, “he”, “was”, “most”, “aligned”, “with”, “my”, “values”, “she”, “said”, “.”, “[SEP]”]] spkeakers [[“[SPL]”, “-“, “-“, “-“, “-“, “-“, “-“, “-“, “-“, “-“, “-“, “-“, “-“, “-“, “-“, “-“, “[SPL]”]] 화자 구분 자, 한 명이 말한 경우 모두 빈 문자열 subtoken_map [0, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 13, 13] 원래 단어의 위치 정보 -
출력 데이터 예시
컬럼 명 값 설명 predicted_clusters [[[4, 4], [6, 6]], [[1, 1], [11, 11], [13, 13]]] 상호참조해결
[[“[CLS]”, “I”, “voted”, “for”, “Obama”, “because”, “he”, “was”, “most”, “aligned”, “with”, “my”, “values”, “she”, “said”, “.”, “[SEP]”]]top_spans [[1, 1], [2, 2], [4, 4], [6, 6], [11, 11], [13, 13]] 멘션 (voted는 모델의 에러로 보임)
[[“[CLS]”, “I”, “voted”, “for”, “Obama”, “because”, “he”, “was”, “most”, “aligned”, “with”, “my”, “values”, “she”, “said”, “.”, “[SEP]”]]head_scores [ ]
참조
- 설명 블로그
https://gnoej671.tistory.com/15 - 참조 논문
http://kiise.or.kr/e_journal/2014/11/JOK/pdf/15.pdf
포인터 네트워크를 이용한 한국어 대명사 상호참조해결
- spanBert 정리 블로그
https://jeonsworld.github.io/NLP/spanbert/
https://vanche.github.io/spanbert_roberta/
https://ettrends.etri.re.kr/ettrends/183/0905183002/0905183002.html -> 트랜스포머 모델 종류별로 설명 잘되있음
- RGCN-with-BERT
https://github.com/ianycxu/RGCN-with-BERT