Look Again at the Syntax: Relational Graph Convolutional Network for Gendered Ambiguous Pronoun Resolution
1. 논문 설명
상호참조해결을 위한 모델
kaggle 대회 코드
github : https://github.com/ianycxu/RGCN-with-BERT
paper :https://www.aclweb.org/anthology/W19-3814.pdf
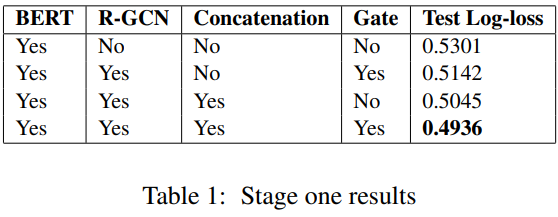
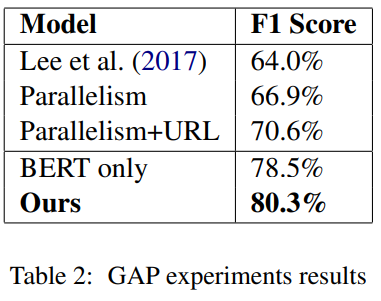
기존 Gendered Ambiguous Pronouns (GAP) 데이터 배이스 라인 기준으로 최고 성능이 66.9%인데 BERT를 base로 한 R-GCN모델을 사용해서 80.3의 f1 score를 달성했다.
위 모델은 대용어해결(대명사)가 가리키는 중심어를 구분하기 위한 모델이다.
중심어의 대상은 남, 여 성별 구분을 기본으로 하며, 확장하여 일반적인 상호참조해결 모델까지 해결을 목표로 한다.
- 상호참조해결에 대한 설명은 아래 링크 참조
https://whtngus.github.io/nlp/2020/08/13/deep_learning_coreference_resolution.html
2. RGCN-with-BERT모델 특징
- BERT 모델의 fine-tuning을 하지 않는다.
BERT모델의 representation vector를 사용하며 학습에 사용되지 않는다.
논문에서는 나오지 않지만 이유는 kaggle대회 특성상 학습 시간단축 및 모델 간편화를 위해 사용하려고 보임
코드 내에서도 bert의 출력부분과 RGCN코드가 나뉘어 있음
- BERT의 output과 RGCN을 이용하여 3가지 모델을 비교 평가함
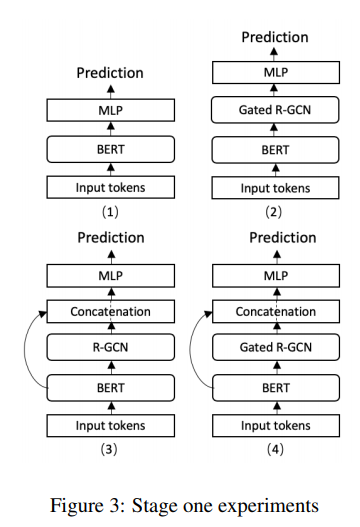
- BERT -> 비교를 위한 base 모델
- BERT+ Gated R-GCN
- Bert + R-GCN (with bert output concatenation)
- BERT + Gated R-GCN (with bert output concatenation)
- R-GCN의 그래프
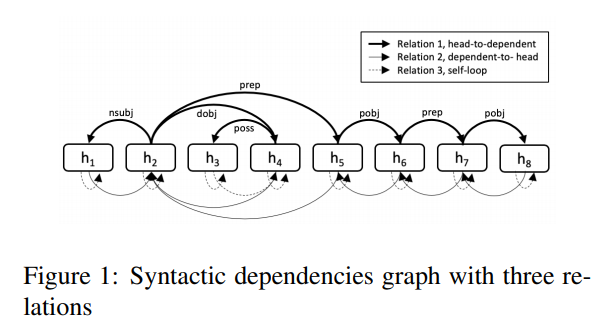
GCN 그래프에 Bi-direction 및 self node를 위해 자기 자신을 향한 loof노드를 생성
- Relation dependent
- bi-direction 1
- self-loop
3. RGCN-with-BERT모델
- 모델의 입력과 출력
| 입력 데이터 | 비고 | 예시 |
|---|---|---|
| 토큰 정보 | 문장 embedding | 문장… |
| 대상 offset 정보(대명사) | 그, 그녀 등 | his, 3(start index) |
| 중심어 후보 1 | 대명사가 가리키는 중심어 후보 | Abram, 33, False |
| 중심어 후보 2 | 대명사가 가리키는 중심어 후보 | Appter, 135, True |
- 입력 데이터
| 출력 데이터 | 출력 데이터는 셋 중 하나만 True 이다. | |
|---|---|---|
| 중심어 후보1이 중심어인지 여부 | True or False | |
| 중심어 후보2이 중심어인지 여부 | True or False | |
| 중섬어 후보1과 2가 관계가 있는지 여부 | 후보 1과 2가 둘 다 Flase인 경우 | True or False |
- 출력 데이터
- 기본적으로 모델은 bert의 output을 대상으로 생성한다.
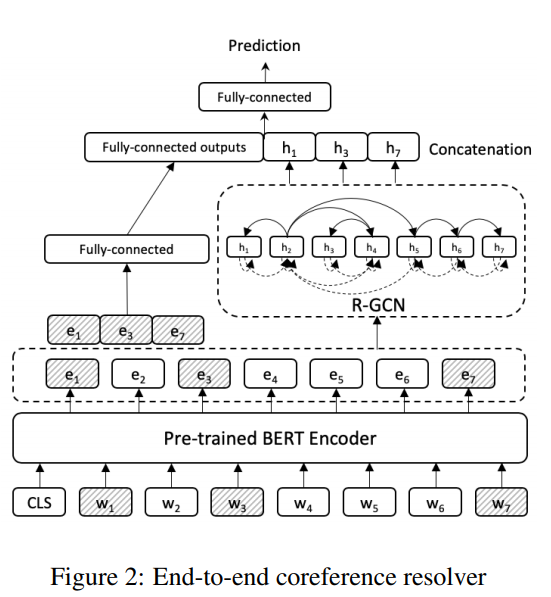
위 그림의 w1, w3, w7의 음영진 부분은 중심어와 대용어해결(대명사) 이다.
- R-GCN
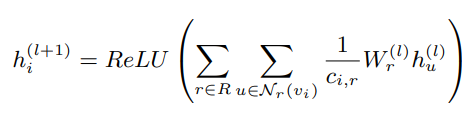
u : 노드
v : 각 노드 히든 스테이드 와 특징
r : 가중치 관계 (weight under relation)
N : 이웃 노드
v : 엣지
c : 노드의 진집 차수 (정규화 역활)
w : weight (모든 엣지 l과 공유됨)
h : 히든 스테이트
l : 레이어 번호
각 노드(토큰)에서 relation 별로 모든 노드를 생성 (셀프 연결 포함)
각 관계(이웃 노드)와 노드별 모든 그래프를 그려 학습을 함.

그러나 출력이 많아지고 중요한 부분에 집중하기 위해 gate value ranging 을 위해 sigmoid를 추가한다.
- 기타
- 위의 R-GCN모델을 해결하기 위해 Deep Graph Library (DGL)라이브러리를 이용한다.
-> 사용하기 매우 어려움 ㅠ
학습용 데이터의 부족으로 5-fold를 이용해서 평가를 함
2454개의 학습 데이터 셋과 2000개의 평가 셋(나중에 공개됨으로)
4. 시험 평가
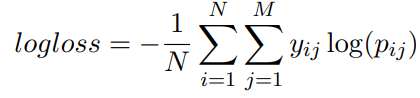
loss 함수