Tacotron
Tacotron
- tacotron2
Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
https://arxiv.org/pdf/1712.05884.pdf - tactron1
Tacotron: Towards End-to-End Speech Synthesis
https://arxiv.org/pdf/1703.10135.pdf
history 기존 STT 모델들
- WaveNet(2016)
정리함 - DeepVoice(2017)
- Char2Wav(2017)
Tacotron 이란?
Tacotron v2 - 2018년도에서 구글에서 발표
Tacotron v1 - 2017년에 구글에서 공개한 TTS 모델
Encoder-Decoder 구조
Tacotron v2 논문에서 사람이 직접 내는 음성과 비슷한 퀄리티의 음성을 생성해 낸다고 밝힘
- 특징
텍스트를 입력으로 받아서 Raw Spectrogram을 바로 생성할 수 있음
간단하게 <text, audio> 페어를 이용하여 End-to-End로 학습이 가능함
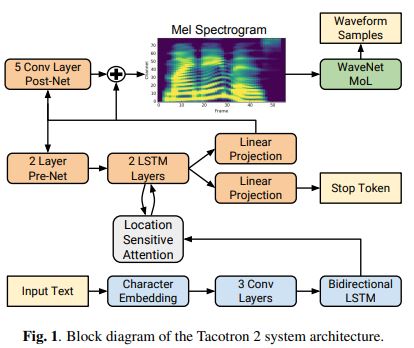
위 사진(tacotron 2 system architecture)을 보면
입력 Input Text를 받아서 Weaveform Samples(음성)이 나오는것을 볼 수 있음.
- 위 모델의 장점
End to End 이기때문에 방대한 Domain 전문 지식이 비교적 덜 필요하다. 트레이닝시 파이프라인을 나눌 필요없다(나눌 경우 에러가 누적될 수 있음).
노이즈 데이터에 더욱 강하다
발화자, 언어, 감정 등의 Feature 등을 손쉽게 조절이 가능하다.
tactron 설명

기본적인 구조는 Encoder-Decoder 구조와 Attention Mechanism을 적용한 구조이다.
Atention RNN 은 GRU Cell을 사용
3개의 output중 가장 오른쪽 하나의 spectrogram이 다음 시퀀스의 인풋으로 들어감
Encoder 설명
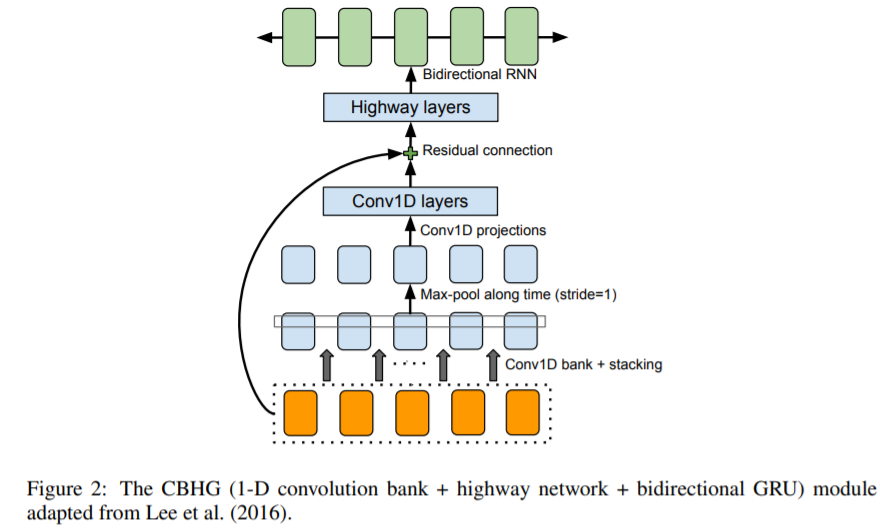
인코더 부분과 CBHG (1-D convolution bank + highway network + bidirectional GRU) 설명
- Character embeddings
위 그림 의 입력은 캐릭터 임베딩이다.
영어의 경우 캐릭터 단위로 임베딩을 하는것
한국어의 경우 경우의 수가 많아 어떻게 임베딩을 할지 찾아봐야 함 *
- pre-net
논문에서 pre-net은 위사진의 Encoder의 경우 아래와 같이 사용되었다.
FC-256-ReLU → Dropout(0.5) → FC-128-ReLU → Dropout(0.5)
Decoder의 경우(참고)
FC-256-ReLU → Dropout(0.5) → FC-128-ReLU → Dropout(0.5)
- 1-D convolution bank
인코더의 경우 Kerner 사이즈를 16개를 사용하는 1-D 모델이다.
- 논문에서 인코더의 경우
Conv1D bank: K=16, conv-k-128-ReLU Max pooling: stride=1, width=2 Conv1D projections: conv-3-128-ReLU
→ conv-3-128-Linear
- 논문에서 디코더의 경우 (Post-processing net CBHG)
Conv1D bank: K=8, conv-k-128-ReLU Max pooling: stride=1, width=2 Conv1D projections: conv-3-256-ReLU
→ conv-3-80-Linear
1D Convolution을 수핸한 후에 그 결과들을 concat하여 (이 과정에서 Max polling 포함되어 있음)
다시 1D Convolution을 수행 후다음 단계로 넘어간다.
(각각의 1D Convolution 이후에 Batch Normalization을 수행)
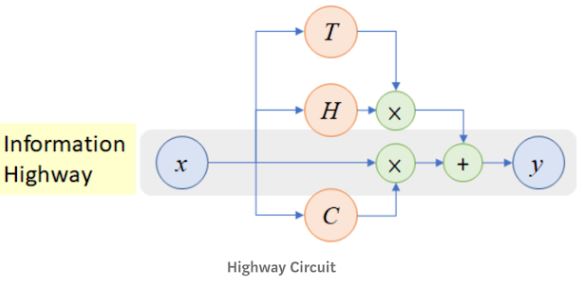
- highway network
1-D convolution bank 의 결과와 입력 캐릭터 임베딩의 Residual connection을 입력으로 받는다.
Highway Network는 Gating 구조를 사용하는 Residual 네트워크이다.
Residual 네트워크는 간단하게 다음과 같이 표현할 수 있다.
Residual(x)=R(x)+x
위처럼 입력과 출력을 더하는 방식은 Vanishing Gradient 문제를 해결하기 위하여 고안된 구조
(Backpropagation 시 R(x)를 생략하여 입력으로 바로 Backpropagation을 전달할 수 있기 때문에)
- Highway 수식
Highway(x)=T(x)∗H(x)+(1−T(x))∗x
T : Transform Gate (Sigmoid Function -> 0~1 값이 나와야 함으로)
C : Carry Gate
C와 T는 "C = 1 - T"의 관계를 같는다.
-> T=0 이면 입력 값이 어떠한 변형 없이 바로 출력이 됨
-> T=1 이면 네트워크에 의해 변형된 값이 아웃풋 값으로 나온다.
따라서 output y는 다음과 같다
IF T(x,Wt)=0, y = x
IF T(x,Wh)=1, y = H(x,Wh)
T(x) 를 Transform Gate라고 하는데 여기서 중요한 점은 T(x)의 Bias는 무조건 -1과 같이 음수로 초기화를 해야한다.
-> 이유 모르겠음
- 인코더와 디코더의 레이어
Highway net: 4 layers of FC-128-ReLU
- Bidirectional GRU
Highway의 결과를 Bidirectional GRU의 입력으로 한다.
Forward 시퀀스와 Backward 시퀀스를 Concat하여 출력
- 논문에서 인코더, 디코더 의 경우
128 cells
Decoder 설명
Encoder와 매우 유사하여 설명 생략
Pre-net을 지난 후 Attention RNN 셀과 Decoder RNN셀을 거친다. (상단 그림 참조)
Attention RNN 셀은 GRU 셀로 구성
Decoder RNN 셀은 Residual GRU Cell로 구성
디코더는 최종적으로 Mel-Spectrogram을 출력
* 여기에서 Reduction Factor r을 이용하여 여러 프레임을 동시에 생성 -> 논문에서는 3개 생성
한 타임 스텝에서 3개의 프레임에 해당하는 Mel-Spectrogram을 생성 후 우측에 있는 하나를 다음 디코더의 입력으로 활용
(음성 신호의 연속성 때문에 여러 프레임에 거쳐서 하나의 발음이 수행되기 때문에 이렇게 사용)
Mel-Spectrogram은 PostNet에 해당하는 CBHG를 거치게 되며 최종적으로 Linear-Spectrogram을 생성
Linear-Spectrogram은 Griffin-Lim Algorithm이라는 음성 재구성 알고리즘을 통해서 음성으로 변환
성능
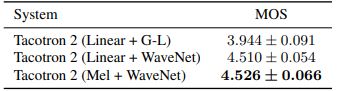
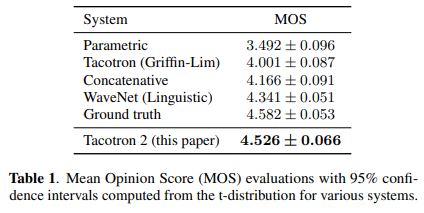
Ground truth 는 실제 음성 데이터
Tacotron 2 의 경우 실제 음성과 거의 비슷한 성능을 보여주고 있다.
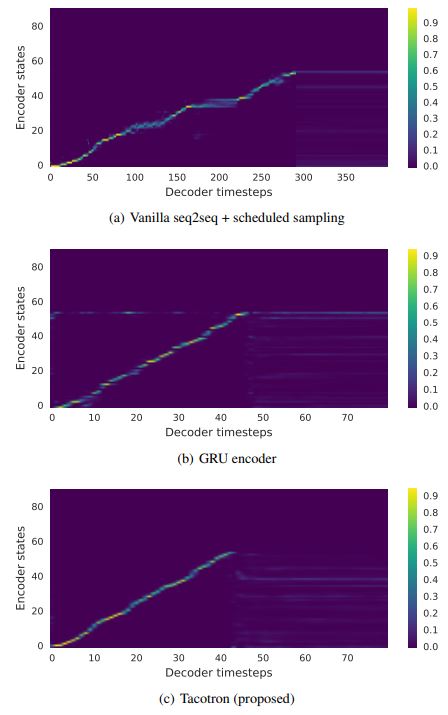
좌측 사진의 경우 Tactron 모델이 입력 데이터에 대해서 Attention이 더욱 뚜렷한것을 볼 수 있다.
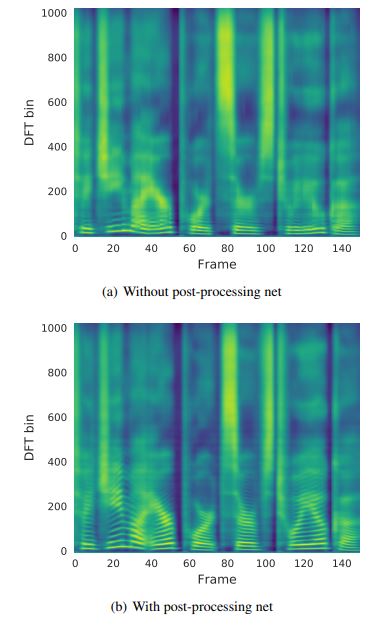
우측 사진의 경우 PostNet을 나눠서 Mel-Spectrogram 및 Linear-Spectrogram을 따로 생성하는 이유에 대한 결
a는 postnet 없이 바로 Linear Spectrogram을 생성한 경우 b는 중간 과정으로 Mel spectrogram을 생성
실제 실행
default로 500 epoch 이지만 1070-TI GPU 기준으로 약 2주간 학습시켜 330 epoch 에서 일단 중지
tensorboard
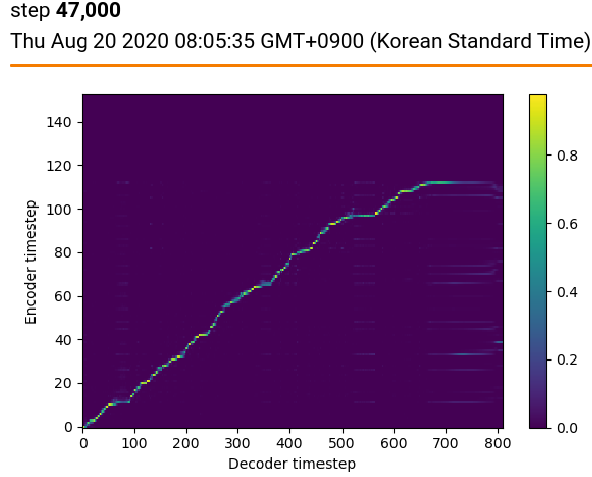
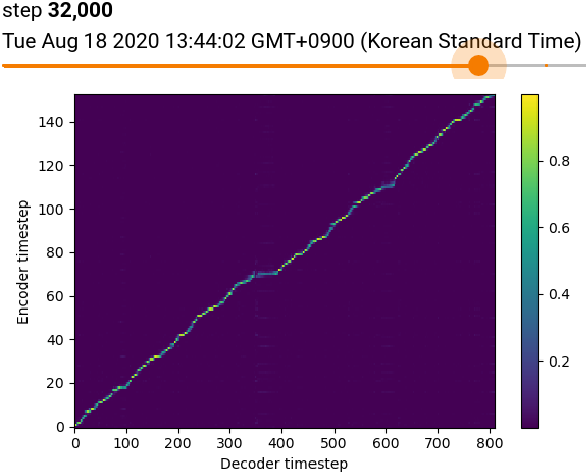
위 사진은 최종 스텝에서 찍은 그래프 아래 찍은 사진은 best로 보이는 스텝
-> tensorboard에서는 안보이지만 172000step 까지 진행
실행 테스트
- 영어로 한국말을 적은 경우
실행 대본 : han kuk mal test
- 영어로 한국 한 경우 테스트
실행 대본 : welcome to ladies and gentlemen
- 느낌표(!) 사용시 변화 테스트
실행 대본 : help me please
실행 대본 : help me please!!!
- 긴 문장에 대한 테스트
- 실행 대본
The current fire house installed within the building used by South Korea’s agency for managing the industrial zone will move to the newly built three-story building, the official said.
- 긴 문장에 대한 attention 그래프
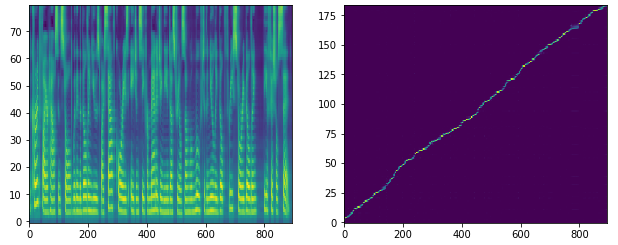
시현 링크
https://google.github.io/tacotron/publications/tacotron2/index.html
정리 참고
- 설명 유튜브
https://www.youtube.com/watch?v=02odSrfgasI - 설명 블로그
https://medium.com/wasd/%EA%B3%A0%EB%93%B1%ED%95%99%EC%83%9D-%EC%8B%9C%EC%A0%90%EC%9C%BC%EB%A1%9C-%EB%85%BC%EB%AC%B8%EC%9D%84-%EC%9D%BD%EC%96%B4%EB%B3%B4%EC%9E%90-e6953caf4bf8
https://hcnoh.github.io/2018-12-11-tacotron - tacoron paper
https://arxiv.org/pdf/1703.10135.pdf - Highway Network
https://jyunleee.blogspot.com/2019/07/highway-network.html
https://lazyer.tistory.com/8