Longformer: The Long-Document Transformer
정보
- 논문 URL
https://arxiv.org/pdf/2004.05150.pdf
- git URL
https://github.com/allenai/longformer
- 게재일
2020-04-10
리뷰
1. 도입
Transformer-based models은 긴 텍스트에 대해서 분석할 수없다.(Attention size 때문에)
이를 해결하기 위한 방법을 제시하고 “text8” 및 “enwik8” 데이터셋 평가(SOTA)
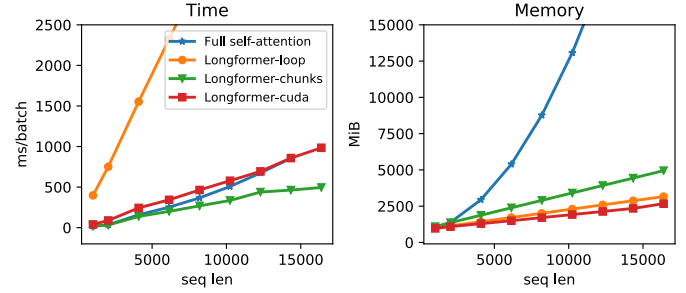
위의 그림처럼 긴 텍스트를 이해하기 위해서 접근한 방식 연산속도 및 메모리 비교
- Full self-attention
Attention을 늘린 경우 토큰 길이 n에 따라 메모리가 n^2으로 상승
- Longformer-loop
Pytorch에서 지원하는 dilation ? 속도가 너무 느려서 test 용도로만 사용가능
각 대각선을 루프에서 별도로 계산하는 방법 (메모리 효율을 위해)
- Longformer-chunks
non-dilated 에만 적용 가능
Attention의 입력인 Q와 K값을 중복되는 값을 연산 ? -> 자세한 내용 따로 정리 필요
2배의 메모리를 사용하는 대신 빠른 연산속도를 보임
- Longformer-cudea
TVM(Tensor Virtual Machine)라이브러리를 사용하여 CUDA kernel을 구현
적은 메모리와 빠른 연산속도를 보임
Downstream Task를 하는 경우에도 긴 문장에서는 RoBERTa 보다 좋은 성능을 보임
2. 모델
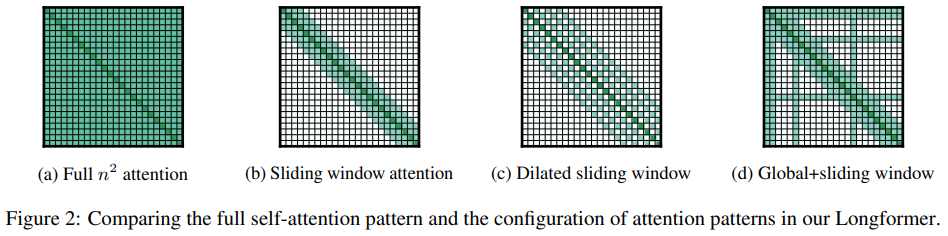
Bert-base 모델에서 긴 텍스트를 임베딩 하기위한 방법
(a) Full attention
어텐션 모델의 사이즈를 늘린다 -> 복잡도 n^2 으로 상승
(b) Sliding window attention
어텐션을 CNN과 같은 방법으로 구성한다.
고정된 사이즈 w 길이를 선택하여 자신을 포함한 앞뒤 w길이의(windows size) 토큰을 Sliding window attention의 입력값으로 사용
그림에서는 3 size의 Attention 이고 Attention을 같은 사이즈로 위로 쌓으면 위의 층일수록 더 긴 문맥 정보를 가질 수 있다.
논문에서는 낮은 층의 Attention에서는 작은 사이즈 높은 층에서는 점차 큰 사이즈로 변경
(c) Dilated sliding window
Dilated 방법을 사용하여 Attention을 쌓는 방법
- Dilated

Dilated는 더 멀리 떨어진 정보를 입력 데이터로 받기 위해 n칸씩 떨어진 값을 입력으로 받음 (설명이 이상해서 하단 그림 참조)
장점으로 많은 토큰의 정보를 취하려면 파라미터가 커져야 하지만 파라미터의 개수를 늘리지 않기 때문에 연산량 관점에서 탁월한 효과를 가지고 있음.
(d) Global+sliding window
Sliding window attention 방법과 추가로 Global Attention 방법을 사용
(b) 와 (c) 방법은 Task Specific한 학습을 하기에 적합하지 않아 전체 토큰을 확인하는 special token을 사용
분류 문제시 [CLS] 토큰, QA문제면 Q전체가 해당 토큰
3. 결과
- Pre-training Data
- Corpus
긴 문서를 사용
RoBERTa 에서 사용한 Book corpus(Zhu et al., 2015)
English Wikipedia
Realnews dataset (1,200 tokens 이상의 데이터만 사용)
- Model
RoBERTa의 leased checkpoint를 약간 변형하여 이어서 학습
-> 기존 BERT모델에서 많은 변화가 필요없음
- Attention Pattern
RoBERTa 를 사용하기 때문에 512 토큰 사이즈를 사용
- Position Embeddings
RoBERTa 의 경우 512 size가최대 값이지만 Longformer에서는 max 값을 4096 사이즈까지 늘려서 사용
- 평가
32256 토큰을 사용 (각 스텝으로 512토큰을 겹치게 해두고 나눠서 사용)
- 스코어 비교

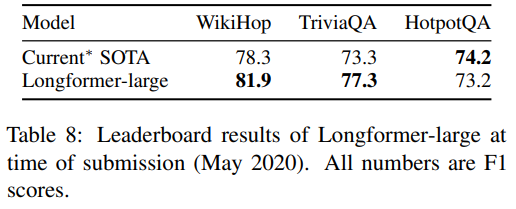
참고 사이트
- Longformer 정리 사이트
https://github.com/modulabs/beyondBERT/issues/12