CogLTX: Applying BERT to Long Texts
정보
- 논문 URL
https://proceedings.neurips.cc/paper/2020/file/96671501524948bc3937b4b30d0e57b9-Paper.pdf
- git URL
https://github.com/Sleepychord/CogLTX
- 게재일
34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, Canada
리뷰
1. 도입
BERT 베이스 모델을 이용하여 긴 텍스트에 대한 임베딩을 하기 위한 논문
BERT는 좋지만 긴 텍스트에 대해서 모델의 입력으로 쓸기 힘든 문제가 있다.
트랜스 포머의 인력 시퀀스 길이(n)이 커짐에 따라 메모리 크기가 n^2 으로 상승
너무 커지는 메모리를 해결하고 긴 텍스트를 문장단위로 임베딩 하기 위한 방법을 제시
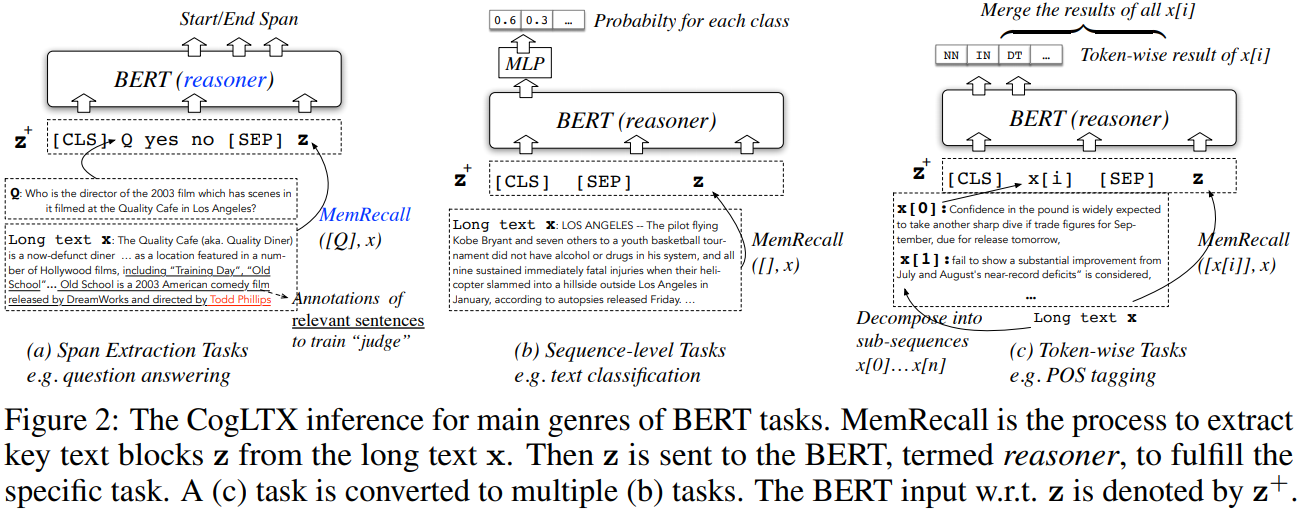
각 테스크에 따라 입력 테스트를 MemRecall 모델을 통해 z를 추출
z는 아래에서 설명(입력 문장에서 필요한 텍스트만을 추출한 압력 텍스트)
2. 관련 설명
기존 BERT의 최대 임베딩 토큰 수는 512개 이다.
BERT-large모델 모델에서 1500 token의 text라면 1 batch size기준으로 14.6GB memory가 필요하다.
-> 벌써 RTX 2080ti(11GB)를 넘어선다.
토큰이 늘어날 수록 O(L^2)만큼 메모리를 차지하게 됨으로 그냥 입력 사이즈를 늘린다면 감당하기 힘들다
3. 모델 설명
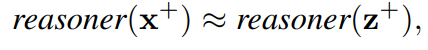
x는 입력 텍스트 z는 논문에서 제시한 방법론을 통해 만들어진 변형된 입력 텍스트 이다.
긴 텍스트 임베딩 방법을 해결하기 위해 z는 x와 같은 효과를 발휘해야 한다.
BERT large 기준으로 512토큰이며 64토큰씩 자르면 8개의 텍스트 블럭을 생성할 수 있다.
여기에서 블럭 구분 시퀀스를 제거하면 63토큰씩 구분할 수 있으며 z의 길이의 총합은 512토큰을 넘지 않는다.
3.1 MemRecall
MemRecall 방법은 입력 텍스트에서 자른 텍스트 블럭들 중 정답을 유추하는데 관련된 블럭들을 추출하는 방법이다.
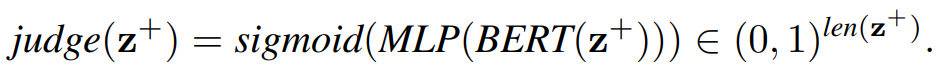
MemRecall 이 각 텍스트블럭이 결과를 도출하는데 관려이 있는지 판별하는 방법이다.
-> 여기에서도 BERT가 사용되는걸 보니 모델 크기가 기본적으로 큼
3.2 Training
MemRecall을 사용하는 CogLTX의 학습 방법은 아래와 같다.
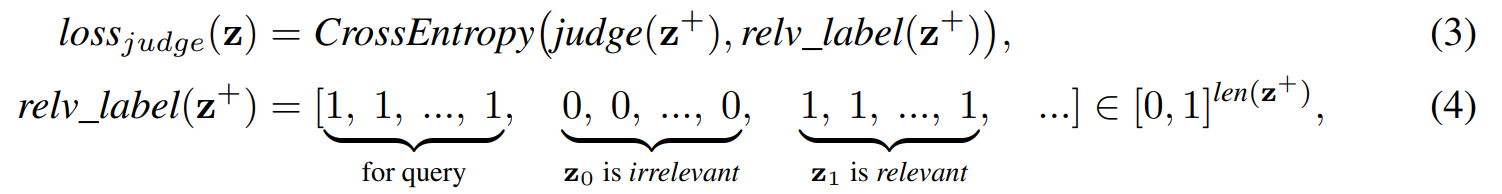
loss 는 CrossEntropy로 구해지며
relv_label은 토큰단위로 query와 관련있는 토큰이 어떤 토큰인지를 맞추는 문제이다.
그러나 관련있는 문장인지 관려있지않은 문장인지 체크되어있는 데이터는 많지 않아 구축되어있지 않는 데이터에 대해서도 학습할수 있는 방법을 제시한다.
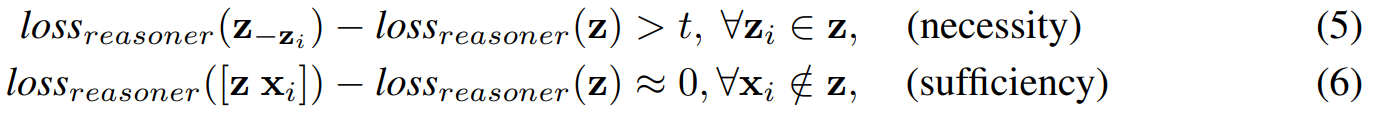
위 t는 threshold 이며 Z-zi 는 Z에서 zi를 제거한 입력이다. 모든 블럭에 대해 진행하며 loss가 증가하면 필요한 블럭 z로 추출할 수 있다.
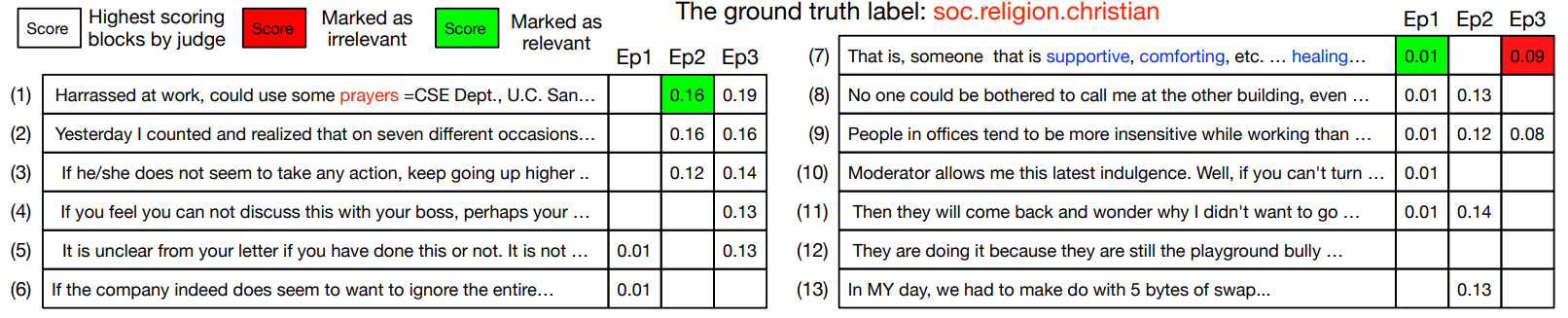
수식의 예시는 위의 그림으로 나타나 있다.
- 그림은 20News 데이터는 라벨이 없는 데이터이다.
처음에는 모두 관련없음으로 체크되며 무작위로 일부 블록을 선택한다.
첫 번째 시도에 7번 블럭이 분류에 기여를 했음으로 관련으로 표시한다.
두 번째 시도에 1번은 강력한 증거 (수식 아래)가 있는것을 발견하고 관련있음으로 체크한다.
세 번째 시도에 7번은 문장에 필수적이지 않으며 관계 없음으로 표시한다.
실험
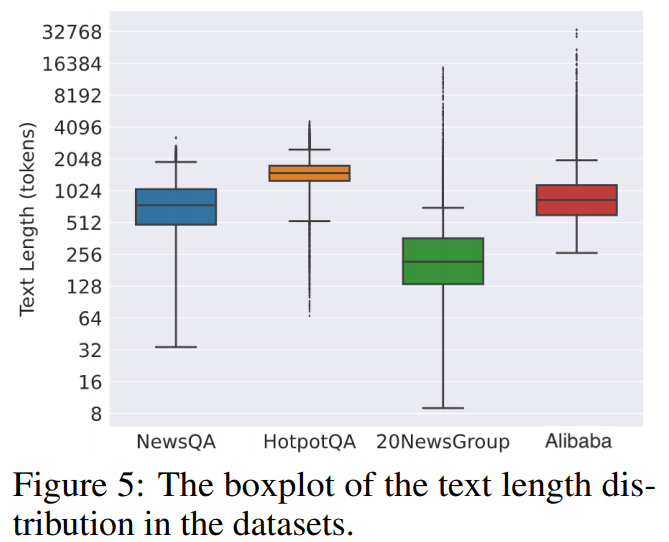
위 사진은 데이터별 토큰 길이분포도 이다.
lr=4*e05를 사용했으며 옵티마이저는 Adam Warmup을 사용했다.
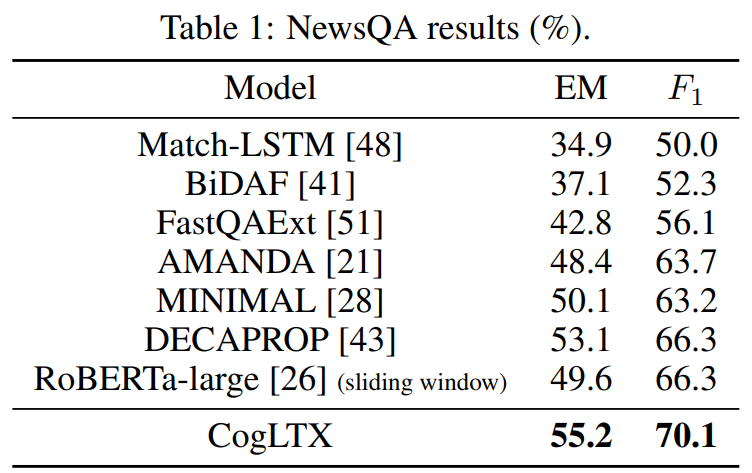
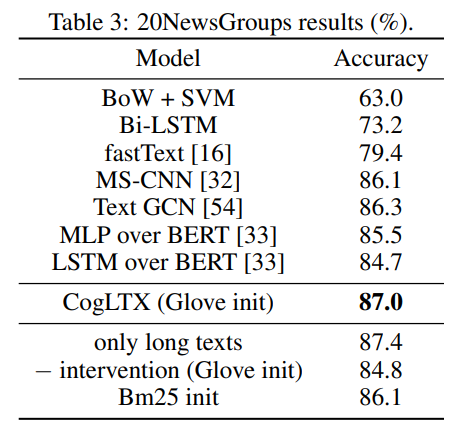
긴 텍스트기반 이어서 그런지 BERT가 sota는 아니다.
table1 - Reading comprehension
table3 - classification
table4 - Multi-label-classification
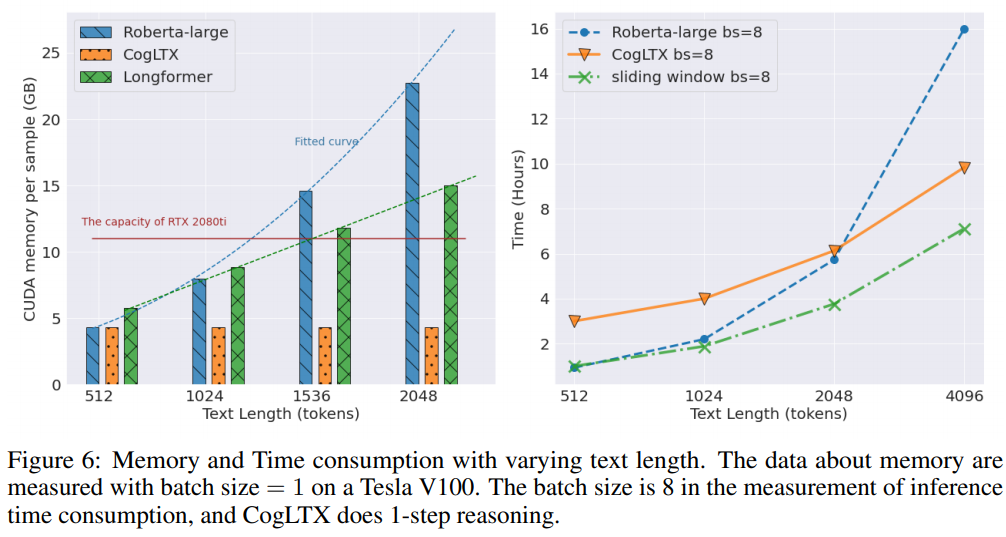
위 사진은 텍스트 길이에 따른 메모리 크기(좌 사진)와 속도(우 사진)을 비교한 그림이다.
sliding windows 같은경우 BERT를 연달아서 predict한 경우로 정확도는 높지 않을걸로 예상된다
비교 대상이 되는 Longformer 모델은 https://whtngus.github.io/paper/2021/01/13/paper_Longformer_The_Long-Document_Transformer.html
정리 참조