Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning
정보
- 논문 URL
https://arxiv.org/pdf/1710.07654.pdf
- git URL
https://github.com/r9y9/deepvoice3_pytorch
- 게재일
2017년 10월 20일(2018년 2월 22일 최종 수정)
리뷰
1. 도입
Text-to-speech(TTS) 논문
- 특징(주로 tacotron과 비교)
Tacotron 논문 다음으로 나온 논문
Tacotron과는 다르게 다중 발화처리가 가능
Tacotron에서 사용하는 recurrent models을 사용하지 않음으로써 모델이 가벼움
2. Model
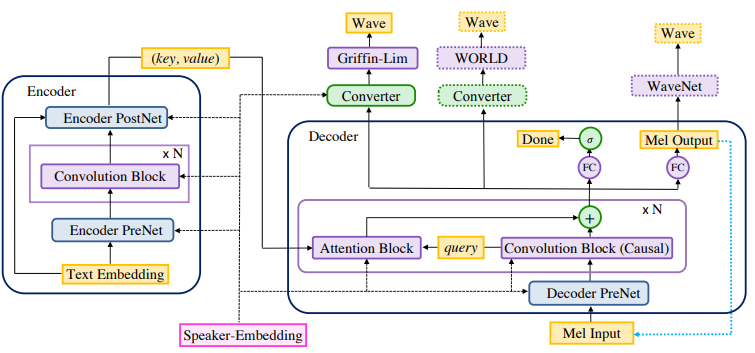
모델의 전체적인 구조이다.
생각보다 tacotron 모델과 유사하며, 다른점은 LSTM 레이어가 없고, Speaker-Embedding이 여기저기 많이 들어간다(다중 발화정보를 처리하기 위해 많은 노력이 보임)
- Encoder(위 그림의 좌측)
fully-convolutional encoder 이며 텍스트를 representation vector로 변환하는 역할
- Decoder(위 그림의 우측)
fully-convolutional decoder 이며 multi-hop convolutional attention 방식을 사용
- Converter(위 그림의 decoder의 위측)
post-processing network, 디코더 모델의 출력을 음성으로 바꿔주는 작업
역기에서는 WaveNet, Griffin-Lim, WORLD 3가지 방법을 사용
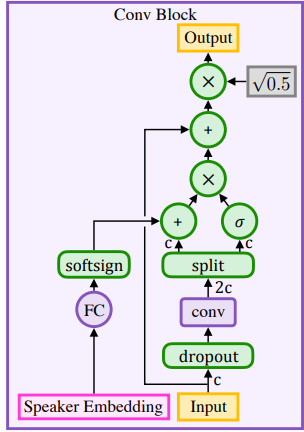
- CONVOLUTION BLOCKS
convs 는 1-D 채convolution 모델
convolution output 사이즈인 2c를 반반 나눠서 하나는 시그모이드 하나는 Speaker Embedding 에 fully connected layer + softsign activation 함수를 통과한 결과와 더해진다.
-> softsign activation(output- -0.8 ~ 0.8)을 사용하는 이유는 출력 음성에 너무 영향을 많이주는것과 포화 문제를 해결한다.
모델 마지막에 왜 0.5^0.5로 정규화(곱하기)하는것은 학습 초기에 입력 분산을 유지하기 위한것
여기에서 음성 정보와 발화자 정보를 조율할 수 있다.
convolution은 시퀀스 길이를 보존하기 위해 (k-1)/2에 해당하는 좌측 timesteps는 제로패딩하게 된다
- ENCODER
encoder 네트워크는 문자 or 음소를 훈련 가능한 representation vector로 변환하는 임베딩 레이어로 시작한다.
시간에 의존적인 텍스트 정보를 추출하기 위해 Convolution Block을 사용하며 이 결과값을 Attention Block의 key값으로 사용된다.
Value 값은 Attention Vector와 텍스트 임베딩 벡터의 합에 0.5^0.5를 곱한 값이다. value는 장기적 맥락 정보와 해당 토큰의 정보를 동시에 고려할 수 있다.
- DECODER
decoder는 encoder에서 준 정보를 기반으로 과거 오디오 프레임 조건으로 하여 다음 음성을 예측한다.
여러 프레임을 함께 디코딩하여 더 나은 음성 품질을 산출한다.
ReLU 활성화 함수를 사용함으로 써 fully-connected layer를 사용한다.
그 다음 convolution block에서 사용되는 dropout은 첫 번째 블록을 제외하고 fully-connected layer의 앞 레이어 이다.
L1 loss(출력 멜 스펙트럼) 와 binary cross-entropy loss(최종 프레임 인지 예측)함수를 사용한다.
- ATTENTION BLOCK
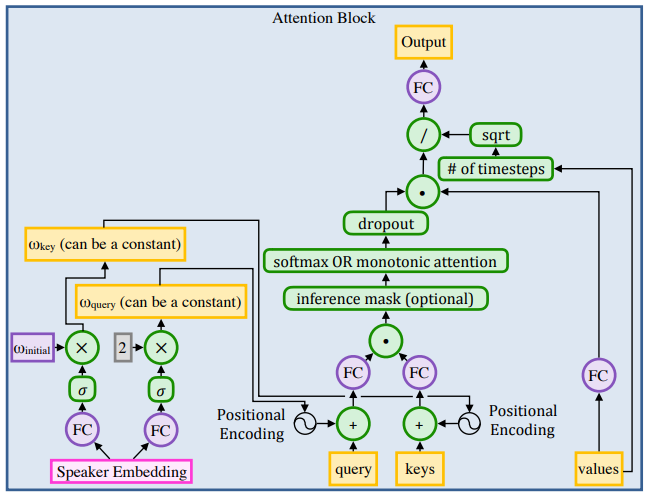
dot-product attention 방식을 사용하며 position embedding은 아래 수식과 같다.
$ h_p(i) = sin(w_s^i / 10000^{k/d}) \quad or \quad cos(w_s^i / 10000^{k/d}) $ \(h_p(i) = sin(w_s^i / 10000^{k/d}) \quad or \quad cos(w_s^i / 10000^{k/d})\)
i는 timestep, k는 channel index, d는 채널 수 이다. (이때 단일 발화지인 경우에는 w를 1로 설정)
3. CONVERTER
1. Grimffin-Lim vocoder
Grimffin-Lim은 spectogram을 시간에 따른 오디오 파형으로 바꿔주는 알고리즘이다.
2. WORLD vocoder
- 현재 프레임이 음성인지 아닌지 -> 음성인 경우 F0 vlaue
- spectral envelope
- 주기성 매개변수
위 3가지를 예측하며 cross-entropy loss(음성인지 아닌지)와 L1 loss를 사용하여 예측한다.
3. WaveNet vocoder
wavenet을 vocoder로 사용 (tacotron2 논문의 아이디어와 유사)
4. Result
- 특징
- Recurrent network를 사용하지 않아 tacotron 에 비해 빠른 학습 가능
500K iter로 학습이 되나 tacotron은 2M iter정도 학습해야함으로 한 배치당 속도 뿐만 아니라 빠른 학습
- Data
VCTK 와 LibriSpeech 데이터셋 사용
VCTK : 108명의 발화자와 약 44시간의 녹음파일
LibriSpeech : 2484명의 발화자와 약 820시간의 녹음파일
- Attention Error Modes
반복 단어, 오발음, 생략 단어등으로 음성합성 품질을 저하시킬 수 있다.
오류발생을 추적하기 위해 100문장 테스트 세트(날짜, 머리글자, URL, 반복 단어, 고유명사, 외래어 등)을 정의하여 표준 주의 메커니즘을 적용
- Multi-Speaker Synthesis
다중 스피커 음성 합성을 효과적으로 처리하기 위해 표준 노이즈 제거를 사용하고 긴 발음을 여러 개로 분할하는 사전 처리 단계를 적용
- Result
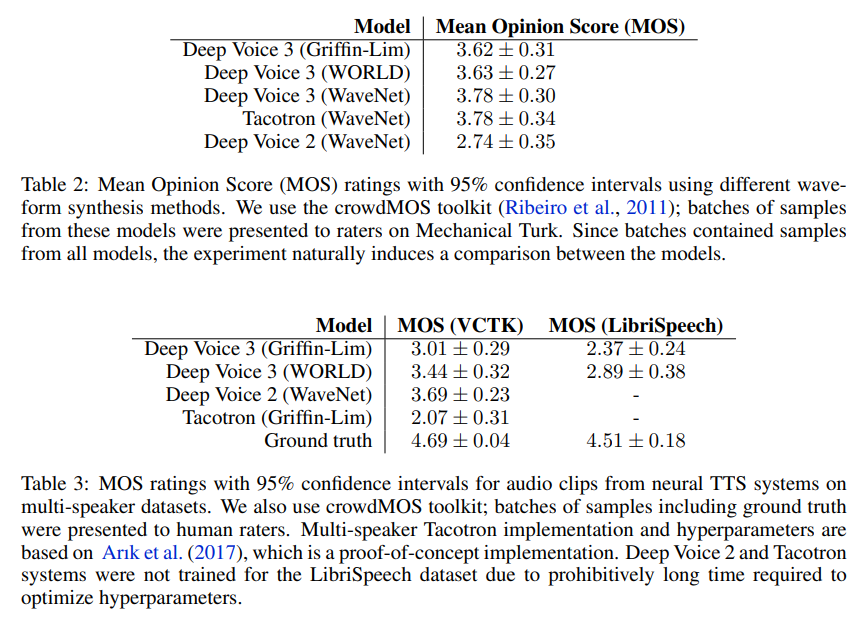
tacotron에 비해 학습속도도 빠르고 모델도 가벼운데 비슷한 정확도를 보인다 (MOS는 개인적으로 언제나 신뢰가 안가지만)
tacotron2모델이 정확도가 더 좋을테지만, 논문에서 제시하는 모델이 더 가벼워지지 않음으로(오히려 추가)
tacotron2에 비해 Deep voice 3의 장점은 다중 발화자와 가벼운 모델로 보인다.