PP-OCR: A Practical Ultra Lightweight OCR System
논문 정보
- 게재일
2020년 10월 15일
- 소속
baidu
- git URL
https://github.com/PaddlePaddle/PaddleOCR
- paper url
https://arxiv.org/pdf/2009.09941.pdf
논문 요약
abstract
paddle OCR은 매우 작은 경량의 OCR System을 제시하는 것을 목표로 한다.
- Model size
- PP-OCR
중국어 6622문자 - 3.6M
영어 63문자 - 2.8M
- 학습 데이터
97K의 텍스트 detection
600K의 direction classifier
17.9M 의 text Recognizer 를 사용
- 모델 지원 언어
한국어
프랑스어
일본어
독일어
영어
중국어
1. Introduction
OCR은 문서 전자화, 금융, 제품 및 자동차 번호판 인식 , 공장 자동화등 많은 곳에서 사용된다.
- Various of Text Appearances
이미지 텍스트 인식 분야는 일반적으로 두 가지 카테고리로 분류된다.
- 장면 텍스트 인식
자연스러운 장면의 사진에서 텍스트를 인식하는 것
이런 사진을 인식하기 위해서는
perspective, scaling, bending, clutter, fonts, multilingual, blur, illumination등의 처리 기술이 필요하다.
- 문서 텍스트 인식
문서에서 텍스트를 인식하는것
장면 텍스트 인식과 같고 high density, long text, 문서 구조 파악 등의 기술이 필요함



- Computational Efficiency
OCR은 많은 컴퓨터 리소스를 필요로 한다.
PP-OCR은 OCR System을 제시를 하고 어떻게 모델 리소스를 줄일 수 있을지를 제시한다.
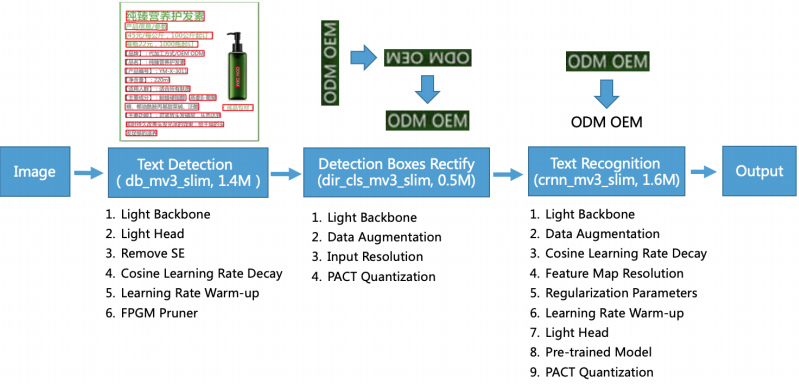
위 사진에서 처럼 PP-OCR은 3가지 부분으로 구성되어 있음
- Text Detection
이미지에서 텍스트가 있는 위치를 파악하는것을 목표로 한다.
Differentiable Binarization (DB) (Liao et al. 2020) 모델을 사용
간단한 segmentation network 모델
위의 모델에서 light backbone, light head, remove SE module, cosine learning rate decay, learning rate warm-up, and FPGM pruner 기법들을 사용하여 모델을 1.4M로 가볍게 만들어서 제공
- Detection Boxes Rectify
Text Detction에서 파싱된 텍스트 이미지들을 수평위치를 맞추는것을 목표로 하는 모듈
간단하게 geometric transformation을 사용
light backbone, data augmentation, input resolution and PACT quantization 기법을 사용하여 500KB까지 모델 크기를 줄임
- Text Recognition
마지막 모듈로 이미지에서 텍스트를 인식해 글자로 바꿔주는 역할을 하는 모듈
CRNN (Shi, Bai, and Yao 2016) as text recognizer를 사용
- Connectionist Temporal Classification(CTC) loss를 사용함으로 써 오버피팅을 피함
light backbone, data augmentation, cosine learning rate decay, feature map resolution, regularization parameters, learning rate warm-up, light head, pre-trained model and PACT quantization 기법들을 적용해 모델 사이즈를 900KB까지 줄이는데 성공
2. Enhancement or Slimming Startegies
- text Detection
introduction에서 말한 text Detction의 6가지 전략에 대해서 설명
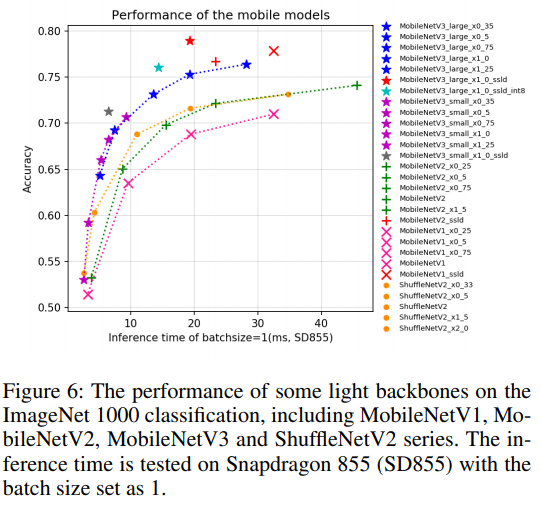
- Light Backbone
backbone이 모델에서 차지하는 용량은 무시할 수 없기 때문에 이를 줄이기 위한 방법을 채택하게 됨.
많은 방법을 시도하였고 MobileNetV3 모델이 가장 효과적이라고 판단 함
논문에서 비교한 모델들 (ResNet, ResNet vd, SEResNeXt, Res2Net, Res2Net vd, DPN, DenseNet, EfficientNet, Xception, HRNet, etc.)
논문에서는 최종적으로 MobileNetV3 large x0.5모델을 사용
- Light Head
FPN (Lin et al. 2017) architecture과 비슷한 구조를 사용
1 × 1 convolution을 사용함으로 써 같은 크기의 채널 맵을 생성하여 모델 사이즈를 줄이는데 집중함 (inner_channels 256 -> 95)
정확도는 미세하게 감소하지만 모델은 7M의 크기에서 4.1M로 줄임
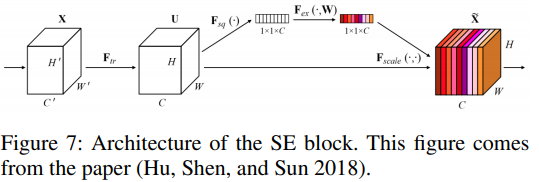
- Remove SE
SE는 short for squeeze-and-excitation (Hu, Shen, and Sun 2018)
모델을 detection하는데 SE block은 좋은 역할을 하지만 큰 사이지의 이미지에서는 많은 시간을 소모하여 backbone에서 제거를 하여 모델 사이즈를 4.1M에서 2.5M로 줄임
- Cosine Learning Rate Decay
Learning rate는 학습 속도에 중요한 역할일 미친다.
local minimum에 빠지지 않으면서 빠른 속도로 최적화 시키기 위해 random initialization과 lerning late를 천천히 감소시키는 기법을 적용
- Learning Rate Warm-up
(He et al. 2019a)에서 사용한 Warm-up 기법을 사용하여 이미지 분류 정확도를향상시킴
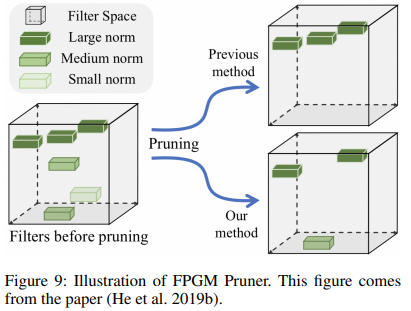
- FPGM Pruner
Pruning은 모델의 효율성을 증가시키기 위한 방법으로 모델의 크기를 줄이는데 효과적
FPGM (He et al. 2019b) 의 방법을 기본으로 사용
Pruning은 각각의 레이어에 대해 민감하기 때문에 FPGM 기법을 각 레이어 별로 수행
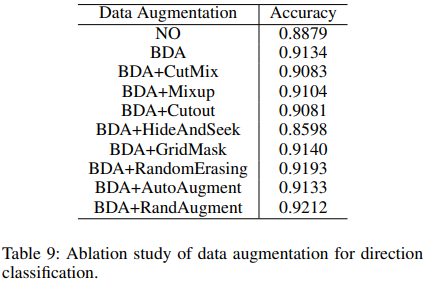
- Direction Classification
- Light Backbone
여기에서도 마찬가지로 MobileNetV3 small x0.35를 사용하여 모델을 경량화 시킴
- Data Augmentation
Towards accurate scene text recognition with semantic reasoning networks 논문에서 사용한 기법을 이용하여 rotation, perspective distortion, motion blur and Gaussian noise 기법을 적용하여 Data Augmentation을 수행
BDA (Base Data Augmentation)기법을 사용하여 트레이닝 데이터에서 랜덤으로 추가
- Input Resolution
normalized image is set as 32 and 100
- PACT Qunatization
Quantization은 두가지로 분류됨
- offline quantization
한번 학습을 하면 바로바로 사용 가능
양자화를 고정된 크기로 사용
KL divergence와 moving average 파라미터등을 사용하여 결정되며 재 학습이 필요 없음
- online quantization
학습시 양자화 파라미터를 결정해야 하는 문제가 있음
less quantization loss 를 사용
RELU 와 swish 를 사용하였고(위 수식은 swish), L2정규화를 적용
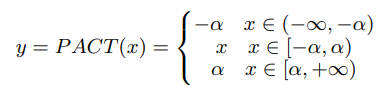
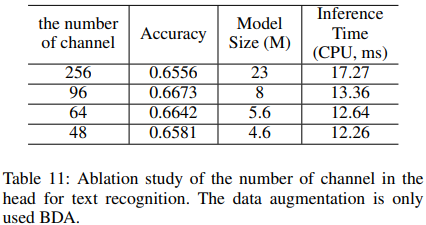
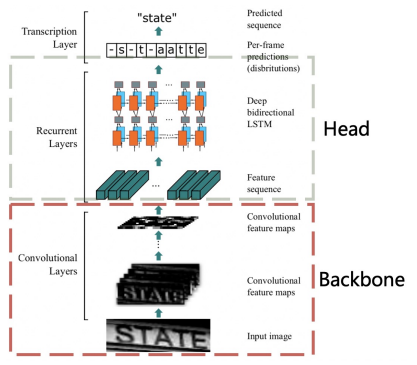
- Text Recognition
위 그림은 CRNN 적용 구조
- Light Backbone
여기서도 마찬가지로 MobileNetV3 small x0.5 를 사용
MobileNetV3 small x1.0을 사용해도 괜찮다고 함
- Data Augmentation
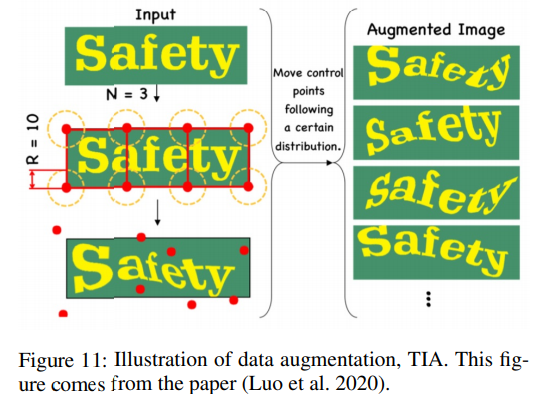
BDA (Base Data Augmentation) 와 TIA (Luo et al. 2020) 기법을 적용
- Cosine Learning Rate Decay
동일한 방식으로 적용
- Feature Map Resolution
CRNN의 높이와 너비가 32,320으로 설정되는데 원래 모델인 MobileNet에 적합하지 않아 많은 텍스트의 수평정보를 유지하기 위해 높이를 반으로 줄이거나 넓이를 반으로 줄이는 등의 작업을 하여 텍스트 인식기의 정확도를 향상시킴
- Regularization Parameters
오버피팅을 막기 위해 사용
weight decay와 L2정규화 등을 사용
- Learning Rate Warm-up
설명 생략
- Light Head
임베딩 차원수를 줄이는 방식을 사용
- Pre-trained Model
Image Net을 학습한 모델을 이용하여 tranformer lkearning을 함
- PACT Quantization
설명 생략
3. Experiments
- 학습 데이터
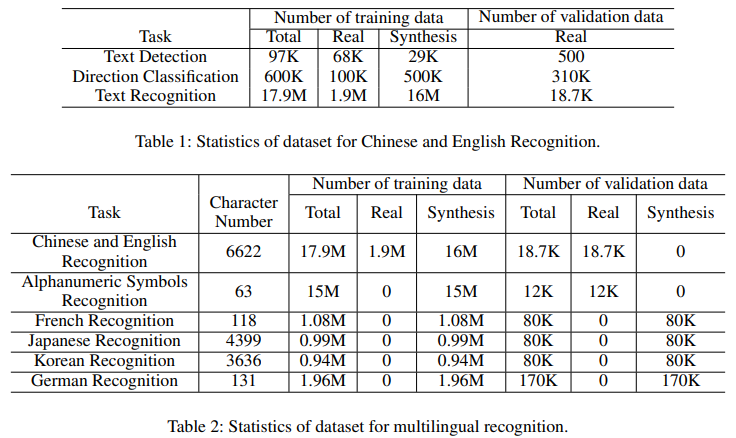
공개된 데이터로는 e LSVT (Sun et al. 2019), RCTW-17 (Shi et al. 2017), MTWI 2018 (He and Yang 2018), CASIA-10K (He et al. 2018), SROIE (Huang et al. 2019), MLT 2019 (Nayef et al. 2019), BDI (Karatzas et al. 2011), MSRA-TD500 (Yao et al. 2012) and CCPD 2019 (Xu et al. 2018) 데이터 들을 사용
- 모델 별 정확도
- text detection
- Direction Classification
- Text Recognition
정확도가 예상한것 처럼 많이 높진 않지만 모델 크기를 생각하면 모바일 에서 접근하기 좋아 보임